Papers-Notes
- SemDedup
- DLRM
- Matryoshka Representation Learning
- Sparse Contrastive Learning for Content-Based Cold Item Recommendation
- Efficient Learning of Sparse Representations from Interactions
- CUDA-L2: Surpassing cuBLAS Performance for Matrix Multiplication through Reinforcement Learning
- Diffusion Beats Autoregressive in Data-Constrained Settings
- Defeating the Training-Inference Mismatch via FP16
- LlamaRL: A Distributed Asynchronous Reinforcement Learning Framework
- Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn’t
- The Super Weight in Large Language Models
- ImageBind: One Embedding Space To Bind Them All
- Scaling (Down) Clip: A Comprehensive Analysis of Data, Architecture, and Training Strategies
- Demystifying CLIP data
- Learning Transferable Visual Models From Natural Language Supervision
- LoRA: Low-Rank Adaptation of Large Language Models
- FrugalGPT: How to use LLM while reducing cost and improving performance
- Mathematics of Deep Learning
- Wasserstein GAN
- Why and How of Nonnegative Matrix Factorization
- DenseNet
- Learning Generative Models with Sinkhorn Divergences
- Improving GANs Using Optimal Transport
- Mask R-CNN
- Fully Convolutional Networks for Semantic Segmentation
- Improving Sequence-To-Sequence Learning Via Optimal Transport
- Memory-Efficient Implementation of DenseNets
- Attention Is All You Need
- Analyzing and Improving Representations with the Soft Nearest Neighbor Loss
- Optimal Transport for Domain Adaptation
- Large Scale Optimal Transport and Mapping Estimation
- Autoencoding Variational Bayes
- Label Efficient Learning of Transferable Representations across Domains and Tasks
- Stacked What-Where Auto-Encoders
- Unsupervised Data Augmentation for Consistency Training
- Towards Federated Learning at Scale: System Design
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Notification Volume Control and Optimization System at Pinterest
- Class-Balanced Loss Based on Effective Number of Samples
- Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
SemDedup
- The Problem: Massive web-scale datasets (such as LAION and C4) are typically only curated for exact duplicates, leaving a significant amount of redundant data that wastes compute and slows down training.
- The Solution: The authors introduce SemDeDup, a deduplication technique that uses embeddings from pre-trained models to identify and remove “semantic duplicates”—data pairs that contain nearly identical semantic information but are not perceptually exact duplicates.
- Training Efficiency: By applying SemDeDup to a subset of the LAION dataset, the researchers demonstrated that up to 50% of the data can be safely removed with minimal performance loss, effectively halving the total training time.
- Performance Boosts: In addition to providing massive efficiency gains for vision-language and language models, removing semantic duplicates with SemDeDup was shown to actively improve the out-of-distribution performance of the models.
- How is it done ? The core “trick” of SemDeDup comes down to how it defines a duplicate and, more importantly, how it manages to find them in a dataset of billions of examples without running out of computing power.
- SemDeDup instead passes the data (like an image or text) through a pre-trained model (like CLIP) to get an embedding.
- The Scaling Trick (In-Cluster Comparison): First, they cluster the data: They use K-means clustering to group all the embeddings into large “neighborhoods” (clusters) of roughly similar concepts. Second, they only compare neighbors: They assume that a semantic duplicate of an image will almost certainly end up in the exact same cluster. Therefore, they only compute the pairwise similarity within each individual cluster.
References
DLRM
- Two feature types, two paths. DLRM splits inputs into dense features (continuous values like price or age — normalized/log-transformed, then pushed through a bottom MLP) and sparse features (categorical IDs like user or item — each looked up in its own embedding table). Both paths emit D-dimensional vectors.
- Dense features collapse to one vector. The bottom MLP fuses all dense features into a single 1 × D vector, while the sparse side produces n × D (one per categorical feature). This is why differing feature counts never cause a shape conflict — there’s only ever one dense vector.
- Everything pools, then interacts pairwise. The dense vector stacks on top of the n sparse vectors into one matrix Z of shape (n+1) × D; Z · Zᵀ then computes the dot product of every pair, giving an (n+1) × (n+1) matrix of scalars.
- Dimensions vs. counts. The dot product requires matching D (guaranteed by construction), but not matching feature counts — it maps any two D-vectors to a scalar. DLRM keeps the upper triangle of unique pairs, flattens it, concatenates the original dense vector, and feeds the top MLP for the final prediction.
References
ImageBind: One Embedding Space To Bind Them All
- This paper presents an approach (imagebind) to learn a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data
- Main idea is that only image-paired data is sufficient to bind the modalities together
- Premise: A major obstacle in learning a true joint embedding is the absence of large quantities of multimodal data where all modalities are present together
- ImageBind does not require explicit paired data between all modalities and instead leverages image as a natural weak supervision for unifying modalities
- An essential concept here is of Feature Alignment - where different modalities get aligned in the same embedding space allowing for zero/few shot learning, and learning without explicit pairs data in training
- The authors use a separate encoder for each modality, and use InfoNCE loss for alignment between I (image) and M (other modalities)
- Images are used as bridges for alignment across different modalities
- This is the same loss as CLIP
- The experiments done in the paper initialize the enocders with pretrained models like CLIP
- Cool result: Embedding space arithmetic where authors add image and audio embeddings, and use them for image retrieval. The composed embeddings naturally capture semantics from different modalities
- Authors claim embeddings from different modalities can boe interchanged - because each embedding space captures semantic meaning transferable to other modalities
- for eg, Upgrading text-based detectors to audio-based, or Upgrading text-based diffusion models to audio-based
- Using a stronger ViT-H (v ViT-B) authors show that stronger visual features learned can improve recognition performance even on non-visual modalities
- Interesting note: batch size used in training varies by modality, depending on the size and complexity of the corresponding pretraining datasets
References
Scaling (Down) Clip: A Comprehensive Analysis of Data, Architecture, and Training Strategies
- This paper does what its name suggests, but also focuses on doing it with less but high quality training data
- The authors perform experiments using zero-shot transfer, linear probing, few-shot classification and image-text retrieval as their evaluation criteria
- For smaller datasets, increasing the training epochs does not yield significant performance improvements on ImageNet. For larger datasets, more training epochs do result in enhanced performance on ImageNet.
- larger datasets and longer training results in improved performance of the trained CLIP models
- Authors compute the similarity between images and texts to create subsets from the dataset
- How do they compute the similarity ? Not answered in the paper
- Models trained on higher quality datasets can outperform models trained on full datasets (i.e. when the models are trained for one epoch)
- We should increase the dataset size for fully benefitting from increasing the ViT model size.
- CNN models perform better with a smaller dataset due to its high inductive bias while ViTs perform better with a larger dataset.
- While SLIP performs better when training on a smaller number of samples compared to FLIP and CLIP (+ augmentation), CLIP with strong data augmentation performs best when training on a larger dataset, except in some tasks
- Check out the references for some interesting papers on generalizibility and scaling CLIP models
References
Demystifying CLIP data
- This paper attempts to reveal CLIP’s data curation, making the entire data pipeline open source.
- MetaClip is trained on training data coming from a highly curated metadata (i.e. metadata refers to “queries”)
- openAI’s clip had 500k queries from which the data was selected
- Curating with metadata and balancing are essential for good data quality, significantly outperforming the use of raw data.
- Paper claims that the essence of success of openAI’s clip lies in their data, specifically in their data curation strategy
- The above is apparent because
- Clip training starts from scratch, avoiding the introduction of biases through filters
- CLIP’s curation process balances the data distribution over metadata, maximizing signal preservation while mitigating, rather than removing, noise in the data
- The key secret behind OpenAI CLIP’s curation is to balance the counts of matched entries (ie keep 20K per query)
- This paper performs many empirical data analysis to prove equal or better performance than OpenAI’s clip
References
Learning Transferable Visual Models From Natural Language Supervision
- This paper demonstrates how to use text to provide supervision to image learning methods for generating SOTA image representations in an efficient and scalable way
- Specicially, this is done by predicting which caption goes with which image
- The key impact is to be able to do tranfer learning to downstream tasks in a zero-shot manner, just by leveraging natural language to reference learned visual concepts
- The contributions are
- create a new dataset of 400 million (image, text) pairs and
- demonstrate that a simplified version of ConVIRT (Zhang et al 2020) trained from scratch, called CLIP, for Contrastive Language-Image Pre-training, is an efficient method of learning from natural language supervision
- study the scalability of CLIP by training a series of eight models spanning almost 2 orders of magnitude of compute and observe that transfer performance is a smoothly predictable function of compute
- CLIP like GPT learns to perform a wide set of tasks during pre-training (OCR, geo-localization, action recognition etc)
- Authors create a large dataset which is key to this research
- 400M (image, text) pairs collected from a variety of publicly available sources on the internet
- To cover a broad set of concepts, authors collected (image, text) pairs where text is one of 500K queries, and sourced 20k pairs per query
- Researchers found training efficieny was key to successfully scaling natural language supervision, and selected pre-training method based on this metric
- Key here was replacing predictive objective for a contrastive objective
- i.e. predicting only which text as a whole is paired with which image and not the exact words of that text
- Learning from natural language also has an important advantage over most unsupervised or self-supervised learning approaches in that it doesn’t “just” learn a representation but also connects that representation to language which enables flexible zero-shot transfer
- Given a batch of N (image, text) pairs, CLIP is trained to predict which of the N × N possible (image, text) pairings across a batch actually occurred.
- To do this, CLIP learns a multi-modal embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of the N real pairs in the batch while minimizing the cosine similarity of the embeddings of the N2 − N incorrect pairings.
- See InfoNCE loss
- To do this, CLIP learns a multi-modal embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of the N real pairs in the batch while minimizing the cosine similarity of the embeddings of the N2 − N incorrect pairings.
- Authors eplain how the simplified the training process compared to other contrastive training techniques (check them out)
- Authors explain the different model architecutures used, and the training recipie used to train the model
- While much research in the field of unsupervised learning focuses on the representation learning capabilities of machine learning systems, we motivate studying zero-shot transfer as a way of measuring the tasklearning capabilities of machine learning systems
- Authors evaluate the task learning ability using few shot transfer, as well as the quality of representation learning using a linear classifier.
- Combining CLIP with self-supervision (Henaff, 2020; Chen et al., 2020c) and self-training (Lee; Xie et al., 2020) methods is a promising direction given their demonstrated ability to improve data efficiency over standard supervised learning.
References
LoRA: Low-Rank Adaptation of Large Language Models
- This paper proposes a technique to reduce the time and memory it takes to perform full-fine-tuning of a LLM, by injecting trainable additional weights instead of performing a full parameter fune-tuning.
- These are trainable rank decomposition matrices injected into each layer of the transformer architecture.
- Inspiration from Li et al. (2018a); Aghajanyan et al. (2020) which show that the learned over-parametrized models in fact reside on a low intrinsic dimension. We hypothesize that the change in weights during model adaptation also has a low “intrinsic rank”.
- What does it mean to have low intrinsic dimension? Answer
- The pretrained model weights stay common, while we only replace the low rank matrices A, B for each task - thus creating LoRA modeules for different tasks.
- See Section 6 for well knows works on making transfer learning / model adaptation more paratmeter and compute efficient.
- Two main ones: adding adaptor layers, optimizing input layer activations
- W_new = W + dW = W + A.B where A and B are low rank decompositions of the weight update
- Through experiments, authors conclude that it is preferable to adapt more weight matrices (Q, K, V, O) than adapting a single type of weights with a larger rank.
- Interestingly, authors measure subspace similarity to find that lower rank value is sufficient - i.e. increasing r doesn’t cover a more meaningful subspace.
References
FrugalGPT: How to use LLM while reducing cost and improving performance
- The premise of this paper is that we can’t call the big LLM for everything, all the time
- We need a way to reduce the costs per task solved by LLMs, and do that by maintaining quality
- In a nutshell, the contribution of the paper is proposing an “ensemble” style approach to utilizing LLMs - have many LLM API handy, figure out when to call which one, reduce costs per call by optimizing on prompt size or using a cache
- They model this problem as an optimization problem - with the goal to maximize the performance while constraining the budget
- Q is the query space, A is the answer space, \(\hat{a}\) is the LLM’s answer, b is the budget constraint and c is the cost per query using strategy s
- The three strategies for cost reduction: prompt adaptation, LLM approximation and LLM cascade
- Prompt adaptation is reducing the prompt length to retain its value but minimizing the input cost to the LLM API (cost is linear to prompt size)
- LLM approximation: make use of a “similar” LLM if the LLM api is quite expensive to call - use a completion cache (dont ask LLM stuff for which you already have an answer)
- this is a simple but can be very powerful: given all queries in the world, it would be a long tailed distribution, but the head load would be ripe for savings as we can save the results of those queries in a cache which serves already asked answer - similar to any search engine or RecSys product
- Another example of LLM approximation is to fine tune a smaller model
- LLM cascade is using a scorer and a router. Say you have a chain of LLMs with ‘smaller’/’cheaper’ ones the first
- Score the output of the first one using a scorer, judge it against a threshold and either use that answer or move to the next bigger LLM in the chain
- Scoring function can be obtained by training a simple regression model that learns whether a generation is correct from the query and a generated answer
- Learning the list of LLMs and the thresholds can be modeled as a constraint optimization problem.
- There are restrictions to these approaches which make the problem nuanced, but overall is a good direction of work that can be leveraged by many small/medium players.
- The authors ran experiments which showed FrugalGPT can match the perf of a big LLM wit upto 98% savings or improve the accuracy by 4% with same cost. Impressive.
References
Mathematics of Deep Learning
- The paper talks about the principles of mathematics which underline the field
- Most of the progress of Deep Learning is empirically stated, but the paper sheds light on numerous aspects of ongoing research to theoretically justify the progress
- There are three main factors in deep learning, namely the architectures, regularization techniques and optimization algorithms
- Statistical learning theory suggests that the number of training examples needed to achieve good generalization grows polynomially with the size of the network
- In practice, this is not the case
- One possible explanatino is that deeper architectures produce an embedding of the input data that approximately preserves the distance between data points in the same class
- Key challenge in deep learning is the lack of a convex loss function to minimize
- Due to non-convextity, the set of critical points includes local minimas, saddle points, plateaus, etc. How the model is initialized and the details of the optimization algorithm play a crucial role
- Common strategy to tackle the non-convexity: Randomly initializing the weights, update the weights using local descent, check if the training error decreases sufficiently fast, and if not, choose another initialization
- Geometrical priors: stationarity and local deformations
- Translation invariance and equivariance
- CNNs leverage these priors
- Convolution + Max-pooling = translation invariance
- The relationship between the structure of the data and the deep network is important
- Research shows that networks with random weights preserve the metric structure of the data as they propogate along the layers
- Each layer of a deep network distorts the data proportional to the angle between the two inputs: the smaller the angle, the stronger the shrinkage of the distance
- The addition of ReLU makes the system sensitive to the angles between points
- Information Bottleneck Lagrangian: minimize the empirical cross-entropy and regularize (KL divergence) to minimize the amount of information stored
References
Wasserstein GAN
- Wasserstein GAN (2017) was one of the first papers of GANs trying to solve the mode collapse problem which is pretty evident in most classical GAN architectures
- Mode Collapse: the network is able to learn only a certain modes (distributions) and hence not generalise properly; the generator learn only limited samples
- Modelling \(P_{\theta}\) is challenging because the distribution is a low dimensional manifold embedded in a very high dimensional space; the true and model manifold’s distribution may not have negligible intersection (singluar support), hence KL divergence won’t work well
- The paper talks about a distance measure which is weak so as to make it easier for a sequence of distributions to converge
- Section 2 introduces and evaluates different types of distance metrics, showing Earth-Mover (EM) distance is the better choice of them all
- The WGANs are based on the dual form of the optimal transport problem
- Because of the continuity and differentiality of the loss function, the critic is trained to optimality eliminating mode collapse
- The better the critic, the higher the gradients we use to train the disciminator
- Importantly, the authors report that no experiment suffered from mode collapse
- Lipschitz continuity plays a major role in the success of the dual form of the EMD
References
Why and How of Nonnegative Matrix Factorization
- NMF is a highly important tool used to extract meaningful and sparse features from a high dimensional matrix
- Most useful applications of NMF are in data mining, document processing, image processing, collaborative filtering, recommendation systems, etc
- Low-rank matrix factorization is representing p-dimensional data points in a r-dimensional linear subspace spanned by basis elements \(w_k\) and the weights \(h_j\)
- The noise model is crucial in the choice of the measure to access the quality of approximation
- NMF aims at decomposing a given nonnegative data matrix X as X ≈ WH where W ≥ 0 and H ≥ 0 (meaning that W and H are component-wise nonnegative)
- NMF is NP-Hard; the unconstrained version of the problem can be solved with SVD though
- NMF is ill-posed; there can be multiple solution to the same problem
- Choice of r is crucial; it can be estimated using SVD, or use trial and error to choose one with lowest error
- Most NMF algorithms follow the general framework of Two-Block Coordinate Descent; eg Alternating Least Squares
- Initialization of the matrices W and H is a challenge; options at hand - randomization, clustering techniques, SVD with \([x]_{+} = max(x, 0)\)
References
Densely Connected Convolutional Networks
- Densenets are a type of deep convolutional networks which try to solve the problem of ResNets
- Instead of having crazy deep nets with identity connections (ResNets), these nets have smaller depth but connect all previous layers to a deeper layer (n * n+1 / 2)
- The feature maps from previous layers are concatenated at every layer
- This way of connection ensures maximum information flow between layers in the network
- This also helps in solving the vanishing gradient problem, and reduces the parameters required as every layer has the information from the previous layers and does not need learn the gradients for it again (feature reuse)
- The authors organise a typical deep DenseNet as a collection of dense blocks (whose all layers are connected to all its previous layers), bottleneck and compression layers
- Having dense blocks allows the use of pooling in between as transitions
- A crucial hyperparameter in DenseNets is growth rate, which is the number of feature maps coming out of a layer; the paper show relatively a small growth rate is sufficient to obtain state-of-the-art results
References
Learning Generative Models with Sinkhorn Divergences
- Training generative models using OT suffers from the computational inefficiency, lack of smoothness and instability
- This paper provides a method to train such models using an OT-based loss called Sinkhorn, based on entropic regularization and utilizing automatic differentiation
- The primal form of the Earth-Mover Distance (EMD) is highly intractable
- Introducing entropic regularization leads to an approximation (Sinkhorn distance) to the full EMD loss
- For \(\lambda \to \infty\) the solution converges to the original EMD and for \(\lambda \to 0\) it forms a homogenous solution (MMD)
- The paper proposes a plan to use minibatch sampling loss and Sinkhorn-Knopp’s iterative algorithm to solve for \(P^{\lambda}_{i,j}\)
- A neural network is used to learn a cost function (acts as a discriminator)
References
Improving GANs Using Optimal Transport
- This paper presents OTGAN which minimizes aa new metric measuring the distance between the generator distribution and data distribution
- This distance called the mini-batch energy distaance combines OT (primal form) with an energy distance
- The dual form of OT resembles GANs formulation, but primal form allows for closed form solutions
- The authors point out the disadvantage of the method used in the paper above, that it leads to biased estimators of the gradients (because of the mini-batch)
- Salimans et al 2016 suggests using distributions over mini-batches
- The distance suggested
where \(\mathbf{X}, \mathbf{X'}\) aare individually sampled mini-bathces from distribution \(\textit{p}\) and \(\mathbf{Y}, \mathbf{Y'}\) are independent mini-bathces from \(\textit{g}\)
-
\(\mathbb{W}\) is the entropy regularized Wasserstein distance, or the Sinkhorn distance; and the energy function is inspired from Bellemare et al 2017 (CramerGAN)
- The cost function \(c\) is learned adversarially, as the cosine distance between two latent vectors (a neural network maps the images into a learned latent space)
- They do not backpropogate gradients through the Sinkhorn algorithm
- Downside: requires large amount of computation and memeory
References
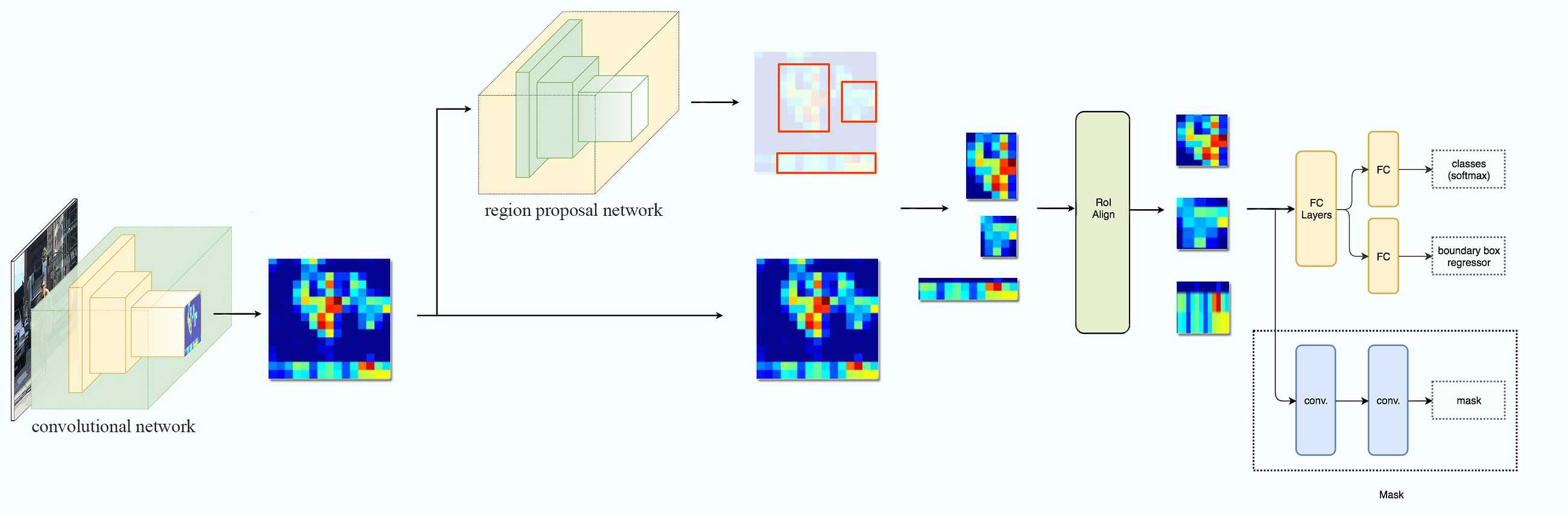
Mask R-CNN
- Extension to Faster R-CNN; adds a masking branch which works in parallel to the classification branch
- RoIPool causes a misalignment; RoIAlign fixes that by having no quantizations
- Predict a binary mask for each class independently, without competition among classes, and rely on the network’s RoI classification branch to predict the category
- The first stage, called a Region Proposal Network (RPN), proposes candidate object bounding boxes
- The second layer extracts features using RoIPool from each candidate box and performs classification and bounding-box regression
- In the second stage, in parallel to predicting the class and box offset, Mask R-CNN also outputs a binary mask for each RoI
- RoIPooling is simple and nice; but it causes the target cells to not be of the same size
- RoIAlign prevents this by using bilinear interpolation over the input feature maps; this causes significant improvement in accuracy
- Non-maximum suppression groups highly overlapped boxes for the same class and selects the most confidence prediction only; this avoids duplicates for the same object
References
{kind=link}
Fully Convolutional Networks for Semantic Segmentation
- The paper details training a fully convolutional network (FCN) end-to-end, pixels-to-pixels on semantic segmentation
- Upsampling is performed in-network for end-to-end learning by backpropagation from the pixelwise loss; upsampling is backwards strided convolution
- The skip architecture is learned end-to-end to refine the semantics and spatial precision of the output
- For final predictions, the net combines the predictions from earlier pooling layers to capture finer details
- Fine-tuning from classification to segmentation gave reasonable predictions for each net
References
Improving Sequence-To-Sequence Learning Via Optimal Transport
- For word prediction tasks, MLE suffers from exposure bias problem
- Attempts to alleviate the issues are i) RL based ii) Adversarial learning based
- OT loss allows end-to-end supervised training and acts asa an effective sequence-level regularization to the MLE loss
- The authors’ novel strategy considers not only the OT distance between the generated sentence and ground truth references, but also the OT distance between the generated sequence and its corresponding input
- The OT approach is derived from soft bipartite matching (see Figure 1 in paper)
- The authors use the IPOT algorithm to solve the OT optimiation problem; though the Sinkhorn algorithm can be used, IPOT was empirially found to be better
- The soft copying mechanism considers semantic similarity in the embedding space
- MLE loss is still require to capture the syntactic structure
- OT losses aare basically used as efficient regularizers
- The authors use Wasserstein Gradient Flows (WGF) to descibe how the model approximately leaarns to match the ground-truth sequence distribution
- In WGF, the Wasserstein distaance describes the local geometry of aa trajectory in the space of probability measures converging to a target distribution
References
Memory-Efficient Implementation of DenseNets
- DenseNets are cool; they save up a lo of parameteres by resuse, but their naive implementation can be quadratic with depth in memory
- If not properly managed, pre-activation batch normaliza- tion [7] and contiguous convolution operations can produce feature maps that grow quadratically with network depth
- The quadratic memory dependency w.r.t. feature maps originates from intermediate feature maps generated in each layer, which are the outputs of batch normalization and concatenation operations
- The intermediate feature maps responsible for most of the memory consumption are relatively cheap to compute; frameworks keep these intermediate feature maps allocated in GPU memory for use during back-propagation
- The authors propose reducing the memory cost by using memory pointers, and shared memory locations; also recomputing the intermediate layers output
- The recomputation comes at an additional cost, but reduces the memory cost from qudratic to linear
- Check out the discussion on why pre-activation batch normalization is necessary and useful; and utility of continguous memory allocations for performing convolutions
- They propose two pre-allocated Shared Memory Storage locations to avoid the quadratic memory growth. During the forward pass, we assign all intermediate outputs to these memory blocks. During back-propagation, we recompute the concatenated and normalized features on-the-fly as needed
- In the code this is implemented using checkpointing
References
Attention Is All You Need
- Generally, language models are comprised of RNNs. Recently CNNs have been used for such tasks (ByteNet, ConvS2S). This paper prexents a novel model architecture called Transformer, which is based entirely on self aattention
- RNNs are inherently serial, not parallelizable; and computatinoaly expensive
- The number of operations required to relate signals from two arbitrary input and output positions grows in the distane between postitions, linearly for ConvS2S and logarithmically for ByteNet; Transformer based model have constant number of operations
- Self-attention is an attention mechanism relating different positions of a single sequence in order to compute a representaiton fo the sequence
- The arch is made up to encoder and decoder stacks, each having modules for sel-attention and point-wise, fully connected layers (similar to 1x1 convolution layers)
- The decoder takes inputs from the encoder’s outputs and the different positions on the query it is decoding (see animation in the Google blog)
- The output of the attention function is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key
- The attention weights are the relevance of the encoder hidden states (values) in processing the decoder state (query) and are calculated based on the encoder hidden states (keys) and the decoder hidden state (query)
- The query is the ‘word’ being decoded; keys are the input sequence, and the output is the sequence with relevance weights, with higher weight on the correct translation for that ‘word’
- The encoder uses source sentence’s embeddings for its keys, values, and queries, whereas the decoder uses the encoder’s outputs for its keys and values and the target sentence’s embeddings for its queries
- Multi-head attention lets the architecure parallelise the attention mechanism; jointly attend to information from different representation subspaces at different positions
- Encoder uses self attention, where it can attend to all positions in the previous layer of the encoder
- The architecture includes masking in the decoder to prevent leftward information flow
- Weight tying is used in the embeddigns and pre-softmax linear transformation layers
- Positional encoding injects some informaation about the relative or absolute position of the token in the sequence
References
Analyzing and Improving Representations with the Soft Nearest Neighbor Loss
- The paper studies internal representations with a loss function, to measure the lack of separation of class manifolds in representation space—in other words, the entanglement of different classes
- They focus on the effect of deliberately maximizing the entanglement of hidden representations in a classifier. Surprisingly, unlike the penultimate layer, hidden layers that perform feature extraction benefit from being entangled, ie, they should not be forced to disentangle data from different classes
- The entangled representations form class-independent clusters which capture other kinds of similarity that is helpful for eventual discrimination
- Since entangled representations exhibit a similar- ity structure that is less class-dependent, entangled models more coherently project outlier data that does not lie on the training manifold
- In particular, data that is not from the training distribution has fewer than the normal number of neighbors in the predicted class
- The entanglement of class manifolds characterizes how close pairs of representations from the same class are, relative to pairs of representations from different classes.
- If we have very low entanglement, then every representation is closer to representations in the same class than it is to representations in different classes; if entanglement is low then a nearest neighbor classifier based on those representations would have high accuracy
- The soft nearest neighbor loss is the negative log probability of sampling a neighboring point j from the same class as i
- Cross entropy loss is minimized and entanglement (soft nearest neighbor loss) is maximised as a regularizer
- This not only promotes spread-out intraclass representations, but also turns out to be good for recognizing data that is not from the training distribution by observing that in the hidden layers, such data has fewer than the normal number of neighbors from the predicted class
References
Optimal Transport for Domain Adaptation
- This paper introduces the theory of optimal transport with application to the problem of domain adaptation, specifically dealing with unsupervised learning
- The domain adaptation problem boils down to i) finding a transformation of the input data matching the source and target distributions, aand ii) learning a new classifier from the transformed source samples
- OT distance make a strong case for such problems because i) they can be evaluated directly on empirical estimates of the distruibutions, and ii) they exploit the geometry of the underlying metric space
- A common stratget to tackle unsupervised domain adaptation is to propose methods that aim at finding representations in which domains match in some sense
- The paper introduces the theory of OT with the intuition to applying it to domain adaptation
- Regulaarization is key in solving OT linear problems, as it induces some properties of the solution; reduces overfitting
- Entropic regularization introduced by Cuturi (and using Sinkhorm computation) is cruical
- Intuition for such a regularization: since most elements of the transport should be zero with high probability, one can look for a smoother version of the transport, thus lowering its sparsity, by increasing its entropy
- As the parameter controlling the entropic regularization term increases, the sparsity of the plan decreases aand source points tend to distribute their porobablity masses toward more taarget points
- The paper provides regularization to the barycentric mapping solution of the transformation mapping source to taaret domains
- But these only cover basic affine transformations, the paper doesn’t provide solutions that can be directly applied to modern deep learning problems
References
Large Scale Optimal Transport and Mapping Estimation
- This paper proesents a novel two step approach for the fundamental problem og learning an optimal map from one distribution to another
- The technique is tested on generative modelling and domain adaptation
- Cuturi’s work on entropic regularization does not scale well, while Wasserstein GANs scale but have to satisfy the non-trivial 1-Lipschitz condition
- First, the authors propose an algorithm to compute the optimal traansport plan using dual stochastic gradient for solving regularizied dual form of OT
- Second, they learn an optimal map (Monge map) as a neural network by approximating the barycentric projection of the OT plan obtained in the first step
- Parameterizing using a neural network allows efficient learning and provides generalization outside the support of the input measure
- The authors use the regularized OT dual formulation; and provide convergence proofs
- The barycentric projection wrt the squared Euclidean cost is oftern used as a simple way to recover optimal maps from optimal transport plans
- The authors claim the restricted application of Courty et al is maily due to the fact that tey consider the primal formulation of the OT problem
- Source saamples are mapped to the target set through the barycentric projection; a classifier is then learned on the mapped source samples
- In all experiments conducted, the squared Euclidean distance is used as the ground cost and the barycentric projection is comptued wrt that cost
References
Autoencoding Variational Bayes
- Encoder encodes x to latent variable z
- Decoder decodes z to x (reconstruction)
- At test time, when we want to generate new samples, we simply input values of z ∼ N (0, I) into the decoder; we remove the “encoder”
- The key idea behind the variational autoencoder is to attempt to sample values of z that are likely to have produced X, and compute P(X) just from those
- We need a new function Q(z|X) which can take a value of X and give us a distribution over z values that are likely to produce X
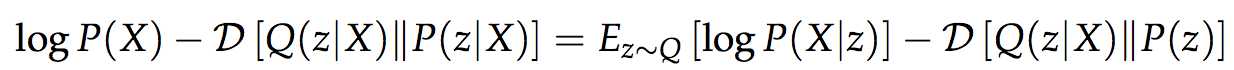
- This equation serves is the core of the variational autoencoder
- We want to maximise logP(X) and the error term, which makes Q produce z’s that can reproduce a given X
- The Q function takes the form of a Gaussian with mean aand covariance as outputs used to model the distribution
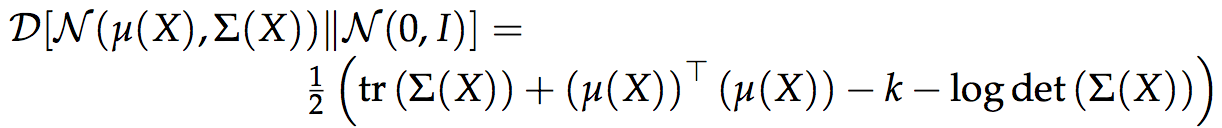
- This equation refers to the last term of the VAE equation, where k is the dimensionality of the distribution
- As is standard in stochastic gradient descent, we take one sample of z and treat P(X|z) for that z as an approximation of the first term on the right
- To prevent the sample from Q(z|X) in the first term on the right during the backprop stage, we use the reparamaterization trick
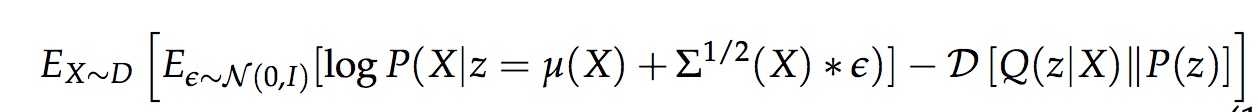
- The second term on the left can be viewed as a regularization term, much like the sparsity regularization in sparse autoencoders
- Refer to figure 4 in the tutorial linked below for a pictorial explanation
References
- Paper
- Tutorial on VAE
- Deep Learning lab slides
Label Efficient Learning of Transferable Representations across Domains and Tasks
- The authors present a novel method to tackle domain shift with a domain adversarial loss, and generalize the embedding a different task using a metric learning based approach
- The framework is applied on transfer learning task from image object recognition to video action recognition
- Given a large label source dataset with annotations for a task A, they seen to transfer knowledge to a sparsely labeled target domain with possibly new task B
- \(\mathcal{X}^{S}\) : source labeled data, \(\mathcal{X}^{T}\) : target labeled data, \(\tilde{\mathcal{X}}^{T}\) : target unlabeled data
- Adversarial discriminative models focus on aligning embedding feature representations of target domain to source domain
- The proposed model jointly optimizes over a target supervised loss \(\mathcal{L}_{sup}\), a domain transfer objective \(\mathcal{L}_{DT}\) and a semantic transfer objective \(\mathcal{L}_{ST}\)
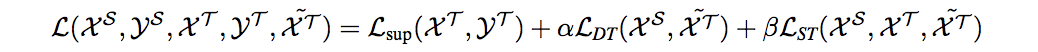
- The domian adversarial loss model aligns multiple layers through a multi layer discriminator
- In particular, a domain discriminator, D(·), is trained to classify whether a particular data point arises from the source or the target domain
- Simultaneously, the target embedding function \(E^t(x^t)\) (defined as the application of layers of the network) is trained to generate the target representation that cannot be distinguished from the source domain representation by the domain discriminator
- \(\mathcal{L}_{ST}\) transfers information from a labeled set of data to an unlabeled set of data by minimizing the entropy of the softmax (with temperature) of the similarity vector between an unlabeled point and all labeled points
- Entropy minimization is widely used in unsupervised and semi-supervised learning by encouraging low density separation between clusters or classes
- For semantic transfer within the target domain, the authors utilize the metric-based cross entropy loss between labeled target examples to stabilize the training and guide the unsupervised semantic transfer
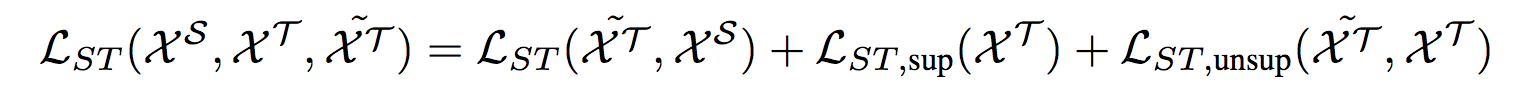
References
Stacked What-Where Auto-Encoders
- The paper provides a straightforward convolutional network based auto-encoder model which can be used in supervised, unsupervised or semi-supervised setting
- ‘What’ refers to information flowing from one layer to the other, input is encoded using conv layers; then decoded using deconv layers
- ‘Where’ refers to how the max-pooling layers choose the output; this information is laterally passed to devon layers to assist in reconstructing the features
- The “what” variables inform the next layer about the content with incomplete information about position, while the “where” variables inform the corresponding feed-back decoder about where interesting (dominant) features are located
- The reconstruction penalty at each layer constrains the hidden states of the feed-back pathway to be close to the hidden states of the feed-forward pathway
- This model is particularly suitable when one is faced with a large amount of unlabeled data and a relatively small amount of labeled data
- \(\mathcal{L}_{NLL}\) is the discriminative loss, \(\mathcal{L}_{L2rec}\) is the reconstruction loss at the input level and \(\mathcal{L}_{L2M}\) charges intermediate reconstruction terms. \(\lambda\)’s weight the losses against each other
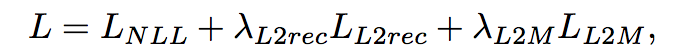
- The model uses negative log-likelihood (NLL) loss for classification and L2 loss for reconstructions
- The SWWAE provides a unified framework for learning with all three learning modalities, all within a single architecture and single learning algorithm, i.e. stochastic gradient descent and backprop
- For semi-supervised learning, all three terms of the loss are active; the gradient contributions from the Deconvnet can be interpreted as an information preserving regularize
References
Unsupervised Data Augmentation for Consistency Training
- This work proposes to apply data augmentation to unlabeled data in a semi-supervised learning setting
- Smoothness enforcing methods simply regularize the model’s prediction to be less sensitive to small perturbations applied to examples (labeled or unlabeled)
- UDA minimized the KL divergence between model predictions on the original example and an example generated by data augmentation
- The authors propose a training technique TSA which effectively prevents overfitting when much more unsupervised data is available than supervised data
- In supervised data augmentation, the goal is to design transformations which lead to correct new training samples, which on training with, lead to a lower negative log-likelihood
- Some tricks for this include, paraphrasing a sentense, back translation, using RL to search for ‘optimal’ combination of image augmentation operations based on validation performances
- Given an input \(x\), compute the output distribution \(p_{\theta} (y \; \| \; x)\) given \(x\) and a perturbed version \(p_{\theta}(y \; \| \; x, \; \epsilon)\) by injecting some noise \(\epsilon\); the noise can be applied to \(x\) or any hidden states
- Minimize some divergence between the two predicted distribution \(\mathcal{D}(p_{\theta} (y \; \| \; x) \; \| \; p_{\theta}(y \; \| \; x, \; \epsilon))\)
- The procedure enforces the model to be insensitive to the perturbation \(\epsilon\) and hence smoother with respect to changes in the input (or hidden) space
- The work minimizes the KL divergence between the predicted distributions on an unlabeled example and an augmented unlabeled example
where \(q(\hat{x} \| x)\) is a data augmentation transformation
- This loss above is used with a weighting factor along with the supervised cross-entropy loss
- Data augmentation can be tailored to provide missing signals specific to each task
- Training Signal Annealing (TSA) gradually releases the training signals of the supervised examples as the model is trained on more and more unsupervised examples
- For ImageNet-10%, the unsupervised training signal from the KL divergence is relatively weak and thus gets dominated by the supervised part
- To counter this the authors employ a number of training techniques
References
Towards Federated Learning at Scale: System Design
- Federated Learning (FL) (McMahan et al., 2017) is a distributed machine learning approach which enables training on a large corpus of decentralized data residing on devices like mobile phones
- The system enables one to train a deep neural network, using TensorFlow on data stored on the phone which will never leave the device; the weights are combined in the cloud with Federated Averaging, constructing a global model which is pushed back to phones for inference
- An implementation of Secure Aggregation (Bonawitz et al., 2017) ensures that on a global level individual updates from phones are uninspectable
- Each round between the servers and the devices takes places in three rounds - selection, configuration and reporting
- The system used ‘pace steering’ to regulate the flow of devices connections; it enables the FL server both to scale down to handle small FL populations as well to scale up to very large FL populations; also help in avoiding excessive activity during peak hours
- The server is based on the actor concurrency model allowing it to scale to millions of devices; it also takes cares of dynamic resource management and load balancing
- All actors keep their state in memory and are ephemeraal; this improves scalability by removing the latency incurred by distributed storge
- Bonawitz et al. (2017) introduced Secure Aggregation, a Secure Multi-Party Computation protocol that uses encryp- tion to make individual devices’ updates uninspectable by a server, instead only revealing the sum after a sufficient num- ber of updates have been received
- The authors imploy Secure Aggregation as a privacy enhancement to the FL service
- To prevent the SA costs from growing with the number of users, the system runs an instance of Secure Aggregation on each Aggregator actor to aggregate inputs from that Aggregator’s devices into an intermediate sum
References
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left aand right context in all layers
- Two existing strategie for applying pre-training language representations to downstream tasks: feature-based aand fine-tuning
- ELMo uses task-specific architectures that include the pre-trainined representations as additional features; OpenAI GPT is trained on down-stream tass by simply fine-tuning ALL pretrained parameters
- The major limiation in standard language models is that they are unidirectional, which limits the choice of architectures that can be used for pre-training
- This work improves the fine-tuning based approach
- Words can “see themselves” in a bidirectional encoder
- To overcome the unidirectionality constraint, they use a masked language model (MLM)
- MLM randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked work based on its conetxt; it lefts the representation to fure the left and right context, which allows pretraining a bidirectinal transformer
- Also the authors propose using “next sentence prediction” task that jointly pretrains text-pair representations
- For a given toke, its input representation is contructed by summing the corresponding token, segment, and position embeddings
- If we used [MASK] 100% of the time the model wouldn’t necessarily produce good token representations for non-masked words
- NSP uses a binary classfication procedure to help the model learn about next sentenses and more context
- The model is fine-tuned for every downstream task
References
Notification Volume Control and Optimization System at Pinterest
- The paper proposes a machine learning approach to decide the notification volume for each user such that the long term engagement is optimized
- Potential point to keep in mind:
- proper objective function that captures long term utility
- non-linear models as simply increasing volume has diminishing returns
- scalable to millions of users
- multiple notif channels, multiple ranking modules, etc
- Weekly Notification Budget: pre-calculted max notification per user
- Budget Pacer: even pacing, space out notifs, minimize user fatigue
- Ranker: after pacing, choose the best notifs from the eligible notifs, pCTR based prediciton
- Delivery: send the notif at the time the user is most likely to engage, track the user response which is used to train models
- Legacy system: hand-tuned frequecy bands based on CTR prediction
- Since the volume is coupled with the CTR prediction, the engagement metrics are driven by the volume of the notification
- Adding new notif types can change the user volume, no control on total volume for a user
- Difficult to isolate the improvment of underlying models, since the volume changes
- Lesson: decouple the volume control system from the type ranking component
- Volume optimization is treated as contrained optimization problem, with given a total number of notifs, try to figure out the optimal distribution amongst users such that overall objective is maximised
- While choosing the objective function, important how to model the long term effect of notifs towards the target metric, which should consider both positive and negative actions from the user
- To directly optimize for site engagement, we should send more notification to user with high incremental value (utlity), instead to those with highest CTR.
- The utility is calculated as \((1 - p(a_{organic}\|u) * p_{CTR}(u)\) to send notifs to those who wouldn’t come to the system organically
- The incremental value of a user \(u\)’s activity \(a\) for the notification \(k+1\) is \(p(a\|u, k+1) - p(a\|u,k)\)
- It’s important to model in the negative actions of a user, along with the positive actions.
- Following a multu-objective optimization system to upper bound the negative actions, and lower bound the positive actions can have issues because different user cohorts behave differently, and such fixed caps may not capture everything
- Consider every notif volume causes a certain user to do a certain action, and this action reflects on the overall user activity
- This can be modelled as an MDP, where each action \(s\) represents a state, \(p(s\|u, k_u)\) is the state transition probability, and \(p(a\|u, k_u, s)\) is the reward function at state \(s\).
- Ideally, each week could be treated as a time step and select a volume for the week \(k_u\) such that the sum of the discounted rewards over the future week is minimized. But this is not very tractable because of unknown user behavior.
- If a user unsubscribes, their long term effect on activity can be modelled
- The final objective function uses 3 models, subscribed activity prediction, unsubscribiton model, unsubscribed long term activity model.
- Using the models we build the objective function and maximise it given the constraints of overall notification volume \(K\) (which is probably limited by product design, backend/delivery capacity).
References
Class-Balanced Loss Based on Effective Number of Samples
- This paper describes how to improve the loss function to take into account the long tail of classes that are not very well represented in the dataset.
- This paper has good foundational information about weighting and sampling techniques; their contribution is two fold
- framework to study “effective number of samples”
- design a “class balanced term” and incorporate into the loss function
- Two common strategies used to help with imbalanced class of data
- re-sampling
- number of samples are adjusted by over-sampling or under-sampling
- (interestingly, there is literature showing under-sampling, i.e. reducing the number of excess samples works better than over-sampling)
- cost sensitive re-weighting
- influence the loss function by assigning relatively higher costs to examples from minor classes
- (check out work on assigning higher weights to “harder” examples - by this can have drawbacks because “harder” samples don’t have to have less training data, and “harder” samnples could also result from label inconsistency, bad training data, or in general noisy data)
- re-sampling
- The typical strategy for re-weighting is to assign weights inversely proportional to the class frequency.
- An improvement on that, is the smoothing version that empricially re-samples data to be inversely propertional to the square root of class frequency.
- This paper tries to provide a holistical framework for re-weighting, by create a balancing term that is inversely proportional to the “effective number of samples of a class” and updating the loss function for the class by that term.
- at one end of the spectrum is no weighting, the other end is inverse class frequency based loss weighting
- this paper suggests using a hyperparameter to find the best performant ‘middle ground’
- The frameworks is based on random covering problem - goal is to cover a large set by a sequence of iid random sets.
- key idea us to associate each sample with a small neighboring region instead of a single point
- capture diminishing marginal benefits by using more data points of a class
- Bunch of assumptions were made before coming up with the formulation, and it was proved by induction (clever)
- Effective number of samples for a class are defined by a hyperparameter \(\beta\), where \(N\) is the total number of samples for the class overall, \(n\) is the number of samples in the ground truth training data
- The loss thus becomes, where \(y\) is one of the class, \(n_y\) is the number of samples in the class \(y\), and \(\beta \in [0,1)\)
- They tested on multiple datasets, changed \(\beta\) and measured net performance. For some datasets, higher \(\beta\) worked well - meaning an inverse class frequency weighting would work well; in some other datasets that didn’t work well and needed a smaller \(\beta\) that has smaller weights across classes.
References
Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
- This work introduces a multi-task learning approach, MMoE, which adds a MoE structure to multi-task learning by sharing the expert submodels across all tasks, while also having a gating network trained to optimize each task.
- It does so by using a multi-gate structure which gates all the tasks, essentially enabling sharing between tasks.
- The general evolution of production netural nets can be thought of as: sparseNN -> SparseNN + moe -> mtml -> mtml + moe -> mtml + mmoe
- The premise of this paper is that when modeling different tasks, the inherent conflicts from task different can actually harm the predictions of at least some of the tasks, particularly when model parameters are extensively shared among all tasks
- An interesting point is how the authors conduct a synthetic experiment where we can measure and control task relatedness by their Pearson correlation.
- The basic building block here the concept of moe - which selects subnets (experts) based on the input at training and serving time. So, that not only improves modeling but also lowers computational costs
- A basic multi model can be represented as \(y_k = h^k (f(x))\) where k are the layers, bottom shared layer is modeled by function f and each tower is functino h
- Orignal MoE representation becomes \(y = \sum^N_{i=1} {g(x)}_i f_i(X)\) where sum of all g equal 1, the i-th logit of the output of g(x) indicates the probability for epert \(f_i\).
- The gating network д produces a distribution over the n experts based on the input, and the final output is a weighted sum of the outputs of all experts.
- In MMoE the output of task k is
- Key takeaway: try using a gating network instead of a ‘switch’ like gate based on the input.
References
Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn’t
- This study tries to make small reasoning models do a good job on certain benchmarks. The key lever is high quality datasets, and RL algorithm (GRPO with reward design). It also tries to highlight insights in training small models - particularly the instability in training them.
- They achieve this by having very strict time and compute restrictions, and truly limit the space within which these small models operate. There might be scope to relax those constraints a bit and squeeze out better performance.
- The findings illuminate the promise of RL-based methods to enhance small LLMs’ reasoning capabilities, achieving competitive performance with minimal resources. Simultaneously, they reveal critical challenges — such as data efficiency, optimization stability, and length constraints - that must be addressed to fully realize this potential.
- By filtering and refining these datasets, the training data is both relevant and challenging, enabling efficient learning for small LLMs. This is a highly subjective process and imaginebly can require many iterations to nail down.
- Authors open source two math based datasets, both filtered using another reasoning model, and based on certain heuristics - s1 and openscaleR dataset.
- Employ a rule-based reward system comprising three components, designed to balance correctness, efficiency, and structure without relying on resource-intensive neural reward models: accuracy reward (final answer to be presented in a \boxed{} format), cosine reward (shorter correct solutions receive higher rewards, while longer incorrect solutions are penalized less severely, incentivizing concise yet accurate reasoning), and format reward (reasoning process within
and tags). - Training is conducted on a cluster of 4 NVIDIA A40 GPUs (48GB VRAM each), imposing constraints that limit us to sampling 6 outputs per step with a maximum completion length of 4096 tokens.
- my take: this can be relaxed for better performance
- Eval: zero-shot pass@1 metric to measure performance, defined as the proportion of problems correctly solved on the first attempt without prior examples.
- After initial increase in perf, there is a drastic drop. This is correlated with unstable accuracy rewards, and varying completition lengths and incoherence after certain steps.
- Incorporating a mix of easy and hard problems under reduced length constraints enhances early performance and stabilizes reasoning behavior, though long-term stability remains elusive.
- For harder tasks, higher context limit might be necessary.
References
The Super Weight in Large Language Models
- Dettmers et al. (2022) discovered that once LLMs reach a certain scale, a small set of hidden state features contains outliers of exceptionally large magnitude. These outliers account for a small percentage of all activations but are crucial for preserving the compressed model’s quality
- However, not all outliers are equally important. In this paper, we study a tiny yet important set of outliers in LLMs, termed super weights. In Llama-7B, pruning the super weight, a single scalar, completely destroys the model’s ability to generate text; the average accuracy of zero-shot down- stream tasks effectively plummets to zero.
- We also find that the super weight amplifies input activation inliers to ultimately produce the exceptionally large magnitude activation observed by Sun et al. (2024) – we term this the super activation. This super activation persists throughout the model at exactly the same magnitude and position regardless of the prompt, and we find this is uniquely enabled by skip connections
- Kovaleva et al. (2021) notes weight out- liers, which emerge gradually, beginning early in pre-training, and cause abnormal spikes at select dimensions in the output embedding vectors. Disabling those outliers significantly degrades both the training loss and the downstream task performance
- Quantization is one of the most popular techniques for reducing LLM resource consumption. How- ever, quantizing LLMs is non-trivial, due to outliers that increase the range of values. Existing works typically study two settings for LLM quantization: (1) Weight-only quantization, where only weights are quantized into low-bit integers; (2) Weight-activation quantization, where both activa- tion and weights are quantized.
- Recent studies have discovered that activation outliers are associated with weight outliers. The hidden dimensions where activation outliers emerge have a high correlation to sensitive weight channels (Heo et al., 2024; Lee et al., 2024). Along these lines, activation magnitudes have been used as an indicator to find salient weight channels to preserve in weight quantization
- Interestingly, the accuracy drop associated with pruning the single super weight is much greater than the effect of all other outliers combined.
- Super weights create super activations.
- SWs can be located by detecting the spikes in the down proj inputs and outputs distributions across the layers. This detection only requires a single input prompt, rather than a set of validation data or use-case examples.
- We find that super weights (1) induce super activations, which have lasting effects throughout the entire model, and (2) suppress stopword likelihood.
- For quantizing based on this knowledge, first, hold out the super outlier to prevent adverse effects on inlier quantization. Second, restore the super outlier’s value after dequantization, to ensure the super outlier’s effects are preserved.
- There exists many ways to workaround super activations, primarily mitigating its effect.
- Scaling with respect to block sizes has a clear trend.
- In block quantization, the large tensor of weights (like in a neural network) is divided into smaller, fixed-size segments called blocks. Each block is then quantized independently using its own scale factor and zero-point, which are calculated based on the range of values within that specific block. This localized approach improves accuracy and reduces the impact of outliers compared to per-tensor quantization, though it adds a slight overhead for storing the additional metadata for each block.
- Smaller blocks: ✅ Better precision (each block optimized for its local range) ✅ Outliers affect fewer weights ❌ More overhead (storing more scale/zero-point pairs) ❌ Slightly slower (more bookkeeping) Larger blocks: ✅ Less overhead (fewer scales to store) ✅ Simpler, faster code ❌ Worse precision (one size fits all) ❌ Outliers ruin quantization for many weights
- As the block size increases, model quality significantly degrades. This decline likely results from the increased quantization er- ror introduced when larger blocks of weights are quantized together, which allows outliers to impact more weights. In contrast, our super weight-aware quantization method demonstrates much greater robustness to larger block sizes. As the block size increases, the degradation in model quality is noticeably smaller compared to the round-to-near method.
References
LlamaRL: A Distributed Asynchronous Reinforcement Learning Framework
- Asynchronous > Synchronous: Running training and generation processes asynchronously in parallel significantly improves throughput and resource utilization by minimizing computational bubbles, with efficiency advantages growing as model scale increases.
- Distributed Model Placement is Critical: Fully separating generator and trainer onto different GPU clusters with independent configurations enables each component to optimize its parallelism strategy (model parallel size, data precision, batch size) without being constrained by the other.
- Off-policy Corrections Enable Stability: Asynchronous training introduces 1 to n steps of delay (off-policyness). AIPO - Asynchronous Importance weighted Policy Optimization with single-sided clipping - effectively mitigates training instability in large-scale training.
- Weight Synchronization is the Bottleneck: Traditional parameter server architectures fail at scale due to network bandwidth and software stack inefficiencies. Fast, GPU-native weight updates are essential for asynchronous RL to work.
- DDMA Solves Weight Updates at Scale: Fully distributed, GPU-native synchronization via direct GPU-to-GPU zero-copy transfers (NVLink for intra-node and Infiniband for inter-node) achieves linear scalability, enabling weight updates for terabyte-scale models across thousands of GPUs in approximately 2 seconds.
- Memory Decoupling Unlocks Optimization: Asynchronous design decomposes shared memory constraints into two independent constraints (trainer and generator), allowing each to be optimized separately for maximum efficiency—this is the theoretical foundation for guaranteed speedup.
- Generation Should Be Offloaded: Generation is memory-bound and contributes significantly to execution time. Complete offloading enhances scalability and flexibility, enabling fine-grained parallelism and quantization optimizations.
- Single-Controller Architecture Scales: Built entirely on native PyTorch without heavyweight external orchestrators (like Ray), using a streamlined single-controller managing executors and communication channels, enabling seamless scaling to thousands of GPUs.
- Flexibility Enables Algorithm Diversity: Modular executor-based design easily supports various RL algorithms (PPO, RLOO, GRPO, RAFT, multi-objective frameworks) by simply reconfiguring models, communication patterns, and data flows without monolithic code changes.
References
Diffusion Beats Autoregressive in Data-Constrained Settings
- Key Takeaway: If you are compute-constrained, use autoregressive models; if you are data-constrained, use diffusion models.
- Diffusion models are a class of generative AI that learn to create data by reversing a gradual noising process. They work by first corrupting training data with noise, then learning to predict and remove that noise step-by-step. In the context of language models, masked diffusion randomly masks tokens and trains the model to predict them in varying orders, unlike traditional left-to-right text generation.
- Diffusion models extract far more value from repeated data - AR models effectively use repeated data for only about 4 epochs before overfitting, while diffusion models can train on the same data for up to 100 epochs with minimal performance degradation.
- Looking at dataset size and available compute budget, one can figure out a threashold when AR will out-perform diffusion
- Diffusion’s advantage comes from implicit data augmentation - By randomly masking different tokens and predicting them in varying orders, diffusion models essentially see many different versions of the same data, unlike AR’s fixed left-to-right processing.
References
Defeating the Training-Inference Mismatch via FP16
- FP16 solves the training-inference mismatch problem: The paper identifies that the root cause of instability in RL fine-tuning of LLMs stems from numerical mismatches between training and inference engines. Simply switching from BFloat16 (BF16) to Float16 (FP16) precision virtually eliminates this mismatch, providing more stable training without requiring complex algorithmic patches.
- BF16’s low precision is the culprit. It has higher range but lower precision, leads to errors which compound in an autoregressive settings, causing the training and inference policies to diverge significantly, leading to biased gradients and training collapse.
- FP16 outperforms all algorithmic corrections. (Better to do it right than add fix-ups later)
- The real trade-off historically has been:
- BF16: Easier to use (no loss scaling needed), wider range, became the “lazy default”
- FP16: Requires loss scaling to handle limited dynamic range, but higher precision
- However, the paper argues that for RL fine-tuning specifically:
- The dynamic range is already established from pre-training
- Loss scaling is now a mature, automated feature (just a config change)
- The precision benefits outweigh any minor implementation complexity
- The real trade-off historically has been:
- Performance hits? Modern GPUs support both equally well: The paper notes that FP16 has been fully supported since NVIDIA’s Volta architecture, and current Ampere/Hopper GPUs have hardware acceleration for both FP16 and BF16. So there’s no inherent efficiency disadvantage to FP16 on modern hardware.
References
CUDA-L2: Surpassing cuBLAS Performance for Matrix Multiplication through Reinforcement Learning
- AI system that beats NVIDIA’s cuBLAS library at matrix multiplication using LLM + Reinforcement Learning. Achieves +22% speedup over torch.matmul, +19.2% over cuBLAS
- Generates actual CUDA C++ code (.cu files compiled with nvcc) - not Python DSLs like Triton
- Uses execution speed as the RL reward - the AI learns to write faster kernels through trial and error; Optimizes across 1,000 matrix configurations (all combinations of M, N, K from 64 to 16384)
- Rewards shorter code → naturally pushes the system toward elegant abstractions; For small matrices: uses raw WMMA intrinsics (simple, fast), For large matrices: adopts CuTe abstractions (enables complex optimizations like multi-stage pipelining without verbose code)
- Even the most heavily hand-optimized kernels can be improved through LLM-guided RL by exploring configuration spaces at scales impractical for humans
- Essentially, use an abstraction (CuTe) as a lever to achieve more than possible with a more-control but lesser flexibility framework (hand written CUDA).
- Extends CUDA-L1 with multi-stage RL training, NCU profiling metrics, and retrieval-augmented context for better optimization decisions
- Multi-stage RL training progressing from broad (general kernel types) to specialized domains (matmul-specific kernels)
- Early stages teach transferable skills, later stages refine domain-specific expertise (specific strategies for matmul)
- Including more comprehensive NCU profiling metrics (e.g., memory throughput, SM occupancy, cache efficiency) in the context
- Incorporating retrieval-augmented context to accommodate new knowledge or architectural characteristics not covered in the foundation model
- This seems very simple and effective, but if nailed right, I’d imagine can land massive gains - you leverage AI to ‘out-source’ the ‘hard’ stuff to humans, use that info well to make smarter choices
- Multi-stage RL training progressing from broad (general kernel types) to specialized domains (matmul-specific kernels)
References
Efficient Learning of Sparse Representations from Interactions
- The paper addresses the memory bottlenecks of large embedding tables in production recommender systems by building on ELSA (Empirical Latent Space Autoencoder). ELSA is a popular linear collaborative filtering autoencoder that maps user interactions using an item embedding matrix \(A\) where rows are constrained to a unit \(\ell_2\)-norm.
- The Core Technique (Compressed ELSA): Rather than relying on post-hoc compression after a model is trained, the authors introduce Compressed ELSA, a training strategy that learns high-dimensional sparse embedding layers during training. It accomplishes this by enforcing row-wise sparsity on the embedding matrix via a deterministic, absolute top-$k$ sparsification operator (\(S_k(A)\)). This operator masks all but the $k$ largest elements in each row, and the remaining active elements are immediately re-normalized to a unit \(\ell_2\)-norm before computing the loss.
- Enforcing extreme sparsity from the very beginning of training can cause a “dead-latents” phenomenon, where certain dimensions never activate or specialize.
- To circumvent this, the core training detail involves a gradual pruning schedule.
- This allows all latent dimensions to participate early before gradually specializing into sparse representations.
- By substituting dense layers with sparse high-dimensional matrices, Compressed ELSA enables perf wins.
- Instead of storing a full 4-byte float for every single latent factor, the model stores compact index-value pairs only for active non-zero elements
- Yields massive storage savings and fast candidate retrieval serving speeds without incurring the steep accuracy penalties typically seen in standard low-dimensional or post-hoc quantized baselines.
- A key detail of learning sparse latent factors is that the active embedding dimensions naturally form an interpretable inverted-index structure.
References
Sparse Contrastive Learning for Content-Based Cold Item Recommendation
- The Problem: Traditional collaborative filtering (CF) recommender systems suffer during “item cold-start” when new items lack historical user interactions. Existing solutions typically try to project auxiliary item content (text, images) into a pre-trained CF embedding space.
- The Bottleneck: This creates a fundamental information gap. CF embeddings capture user behavioral patterns and popularity biases, whereas content features capture semantic attributes. Forcing content to align with behavioral embeddings introduces noise, yields erratic recommendations, and inherits popularity biases.
- The paper proposes abandoning CF alignment entirely. Instead, it advocates for purely content-based modeling where a content encoder maps items into a latent space where item-item similarity directly correlates with user preferences.
- To train this content space without standard CF supervision, the authors introduce the SEMCo (Sampled Entmax for Multimodal Cold-start) framework
- a contrastive, sampled softmax regime
- Standard sampled softmax outputs dense (non-zero) probabilities. In large contrastive batches, this dilutes the supervision signal by calculating gradient updates for thousands of irrelevant negative examples. SEMCo replaces softmax with the \(\alpha\)-entmax family of functions
- Multimodal Content Encoder
- Individual modalities (e.g., text descriptions, images) are mapped through a single layer, batch normalization, and a ReLU activation.
- The hidden vectors are fused using a lightweight attention module (a 2-layer MLP with a softmax output) that computes weights dynamically across modalities.
- The weighted sum is passed through a final linear layer and \(L_2\)-normalized to yield the final representation vector \(y\).
- Interesting take: how does the new latent space based embeddings work with Knowledge Distillation. Since the new space is entirely within the content space, it can transfers item-item similarity structures from a heavy, high-capacity teacher content encoder to a lightweight student content encoder.
References
Matryoshka Representation Learning
- Traditional models produce fixed-size, rigid embeddings that distribute information uniformly across all dimensions. To meet varying downstream compute or storage constraints, users previously had to retrain multiple models or use post-hoc compression, which often resulted in severe accuracy loss or high maintenance overhead.
- Instead of optimizing only the full-sized embedding, MRL modifies the training pipeline by introducing a multi-scale loss function. During each training step, the full embedding is truncated into multiple smaller, nested sub-vectors (e.g., $d/16, d/8, d/4, d/2, d$), a loss is calculated for each scale independently, and these losses are aggregated to backpropagate together.
- This nested optimization forces the model to prioritize and pack the most critical, broad semantic information into the earliest dimensions (the prefix), while later dimensions are restricted to encoding fine-grained, non-critical nuances. As a result, the first $m$ dimensions of a larger vector naturally form a highly coherent, standalone $m$-dimensional embedding.
- This enables improved downstream applications where lower dimensional embeddings can be used without retraining.
- So its like having many, many dimensional embeddings all trained together once for one purpose.